並行執行區塊鏈系統調研
2024-09-02 11:23 金色精選
撰文:PREDA;編譯:ChainFeeds Research
本文的內容和目的
無論是在傳統的數據庫領域還是在區塊鏈技術中,並行執行模型的設計都較爲復雜。 這是因爲,在設計過程中,需要綜合考慮多個維度,而每個維度的選擇都會對系統的整體性能和可擴展性產生深遠影響。本文將深入探討當前最具代表性的幾種區塊鏈執行層並行架構,並詳細呈現我們針對這些架構在性能和可擴展性方面所做的實驗結果。
從一個維度來說,區塊鏈領域一直處在對鏈的高性能和高可擴展性的持續追求中。即使在多鏈系統和 Layer2 系統出現後,每個智能合約的執行能力仍受限於單一虛擬機 VM 的能力。隨着並行虛擬機(Parallel VM)的出現,這一局限得到了突破。並行虛擬機允許單個智能合約的交易在多個 EVM/VM 上同時執行,從而利用更多的CPU核心來提高性能。
我們認爲,在衆多支持並行VM的高性能區塊鏈系統中,Sei(V2)、Aptos、Sui、Crystality 和 PREDA 最具代表性,每個系統都具備設計上的獨特優勢。
在本文开篇,我們展示了第一組實驗結果。下圖展示了在 128 核的機器上,執行相同的ERC20 智能合約時,Sei、Aptos、Sui、Crystality 和 PREDA 的每秒交易數(TPS)的絕對值。從這組實驗結果來看,PREDA 模型在五個並行執行系統的 TPS 和可擴展性比較中佔據了顯著優勢。
其他實驗數據和分析,我們將在後文詳細展开。
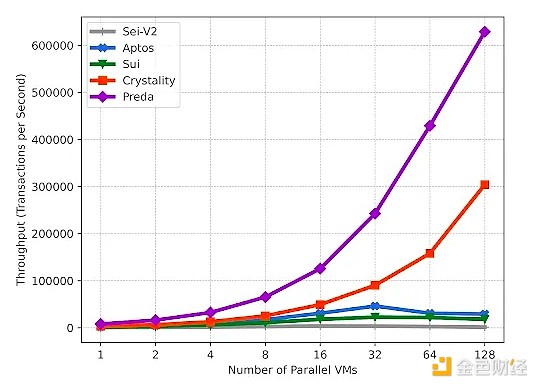
以下,我們將詳細說明我們實驗中的具體方法和操作:
我們首先比較了五個系統的 TPS 值,即吞吐量。在不同鏈上進行的 TPS 對比實驗中所用的交易量相同。
考慮到不同系統中採用的不同編程語言和底層虛擬機不同,單一的吞吐量比較不能完全說明系統的優劣,我們還進行了相對加速結果即 Speedup Ratio 的比較,即同樣數量的交易在多個 VM 相對於在一個 VM 上執行的加速效果。在 Sui、Aptos、Crystality 和 PREDA 中,每個线程都分配了一個專用 CPU core。
所有詳細的實驗數據,包括絕對 TPS 值和加速比,請參閱完整的實驗報告。
下表中展示了實驗中所用的數據來源、實施過程和評估方法。

並行執行模型一覽
Aptos 和 Sui 兩個項目,都衍生於 Meta( 曾名 Facebook)宣告失敗的區塊鏈項目 Diem。兩個項目均由前 Meta 工程師創立——Aptos 由 Avery Ching 創立,Sui 由 Sam Blackshear 創立。二者隨後沿循的技術路线卻不盡相同,Aptos 嚴格遵循爲 Diem 开發的原始 Move 編程語言,但 Sui 對 Move 進行了大量修改。
接下來,我們將探討 Aptos 和 Sui 的並行化模型的差異,分析它們採取的不同方法如何影響性能,並重點介紹它們各自的優勢。
Aptos:採用樂觀並行化的高性能 Layer 1
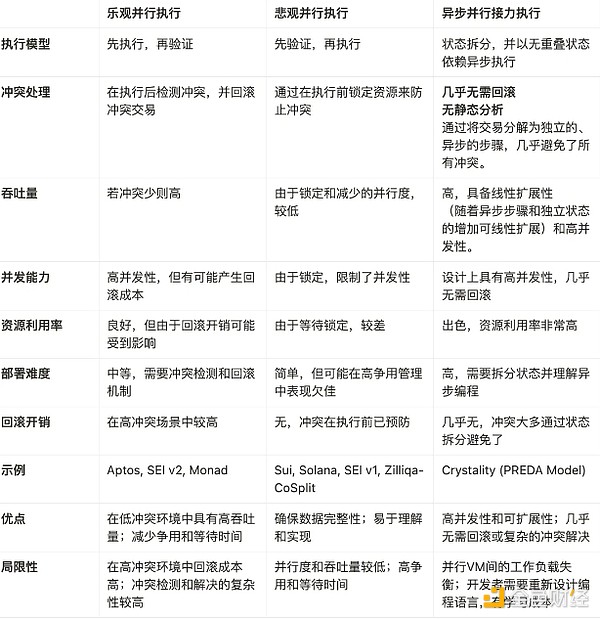
Aptos 是一個 Layer 1,通過樂觀並行化機制實現智能合約的並行執行,從而提升高性能。具體來說在樂觀並行化中,交易被初步假設爲無狀態衝突並以並行方式執行。執行後,系統會檢查衝突,並通過回滾和串行執行方式或通過不同的調度,重新執行衝突交易來解決衝突。這種推測執行方法假設大多數交易不會發生衝突,從而最大化並行執行的優勢,同時提供了處理衝突的備用機制。
樂觀並行化的優勢:(1) 不需要修改程序:無需對現有代碼進行更改即可輕松實現。(2) 在衝突只佔低到中等百分比的場景下的效率:通過允許許多交易並發進行,並在出現衝突時再處理衝突,最大化吞吐量,在許多現實場景中,衝突相對較少。
Aptos 使用 MOVE 編程語言進行智能合約开發,並在系統實現中使用 Aptos MOVE 虛擬機。
Sui:採用悲觀並行化的高性能 Layer 1
Sui 採用了一種悲觀並行化策略。在悲觀並行化中,系統在執行前會預先檢查交易是否可能發生資源爭用。程序員需要指定每筆交易需要訪問的資源(即狀態)。系統對每個接收到的交易進行預檢查,以檢測潛在衝突。只有不涉及與當前執行中的交易發生資源爭用的交易,才會被送至執行引擎進行並行執行。
悲觀並行化的優勢:(1) 避免回滾:通過在執行前識別並避免衝突,此方法最小化了回滾和重新執行的需求,從而實現更可預測的性能。(2) 在高衝突場景中的效率:在高爭用環境中非常有效,確保只有不衝突的交易並行執行,減少衝突解決所帶來的开銷。
Sui 也使用 MOVE 編程語言,但具有自己的 Sui MOVE 擴展,並在系統實現中使用 Sui MOVE 虛擬機。
Sei:與 Solidity 和 EVM 兼容的樂觀並行化
Sei最初推出公鏈時,其定位是基於 Cosmos SDK 構建的交易型應用鏈,現在已升級爲首個並行化 EVM 鏈。在並行執行這一層面,Sei 採用了一種類似於 Aptos 模型的方法,我們稱之爲樂觀並行化。
Sei (V2) 所採用的樂觀並行,其與衆不同之處在於使用 Solidity 編程語言和標准以太坊虛擬機(EVM),確保 EVM 和 Solidity 兼容性。
Crystality 和 PREDA:並行接力執行架構
Crystality 和 PREDA 都支持並行接力執行分布式架構(Parallel Relay-Execution Distributed Architecture)。PREDA 是爲多 EVM 區塊鏈架構裏的並行化通用智能合約而專門設計。二者的關系是,Crystality 是一種用於並行 EVM/GPU 的編程語言,其基礎是 PREDA 模型。從系統的角度來說,PREDA首次在區塊鏈領域,使合約功能的完全並行化成爲可能,因此能最大化一組交易的並發性。這確保了所有 EVM 實例的高效利用,從而達到一定硬件配置條件下的最佳性能和可擴展性。
與 Solidity 和 Move 的順序執行,和Shared Everything的架構設計不同,PREDA 模型首次採用了Shared Nothing架構,以打破並行執行中的狀態依賴,並確保不同的 EVM 實例永遠不會訪問同一片合約狀態,從而幾乎完全避免了寫衝突。
在 PREDA 中,合約函數被分解爲多個有序步驟,每個步驟依賴於狀態中一個可並行化且無衝突的部分。用戶發起的交易首先會被發送到一個持有用戶地址狀態的 EVM 上。在交易執行過程中,執行流可以通過發出接力交易從一個持有當前管理所需合約狀態的 EVM 切換到另一個 EVM的方式,實現數據不動,而執行流根據數據依賴關系在 EVM 之間移動。
五大代表性合約的實驗數據
在我們的評估中,我們測試了五個廣泛使用的智能合約——ETH TokenTransfer、Voting、Airdrop、CryptoKitties 和 MillionPixel,以及 MyToken (ERC20)。這些合約在包括 Sei、Aptos、Sui、Crystality 和 PREDA 在內的各種區塊鏈系統上執行。我們進行了詳細的實驗,以比較不同並行執行系統的性能,重點關注每秒交易量 (TPS) 和加速比,這些指標衡量了在多個虛擬機上與各系統單個虛擬機上執行時相對的性能提升。
所有詳細的實驗數據,包括絕對 TPS 值和加速比,請參閱完整的實驗報告。
ETH TokenTransfer 合約:該實驗使用了與標准 ERC20 智能合約相同的實際歷史 ETH 交易。
Voting 合約:Voting 合約是 PREDA 模型如何簡化並行投票算法的絕好例子。它利用 Crystality 和 PREDA 的數據拆分、接力和執行機制,在絕對 TPS 和加速比上均優於樂觀(Aptos)和悲觀(Sui)並行化方法。原本在 Solidity 中的順序算法現在允許跨虛擬機並行投票,並將結果從臨時數組中聚合。
AirDrop:此合約從一個地址向多個地址觸發多次代幣或 NFT 轉移。它具有一對多的狀態更改模式。在這種情況下,Sei、Aptos 或 Sui 中的兩個交易不能並行執行。只有通過並行粒度更高的PREDA 模型,能使這些交易能夠以流水线模式並行處理。
CryptoKitties:這個合約是以太坊上的一款流行遊戲合約,涉及根據父母貓的基因繁殖子代貓。與前述合約不同,這個合約在處理用戶發起的交易時需要訪問多個地址狀態,包括「父貓」、「母貓」和「新生貓」。該合約在從父母基因中計算新生貓的基因時還涉及比前述合約更復雜的計算。
MillionPixel:在以太坊上的這個遊戲合約中,用戶們要搶先在地圖上標記坐標。這個智能合約用於展示 PREDA 模型的靈活性。除了按地址劃分合約狀態外,程序員還可以定制分區鍵,例如在這種情況下從地址類型切換爲 uint32 類型。
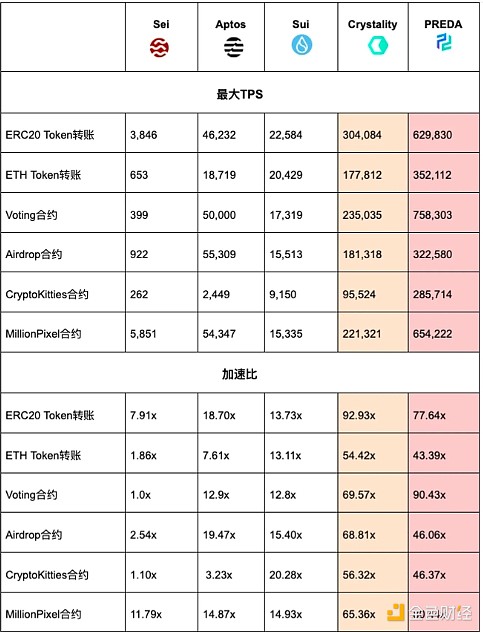
爲了方便讀者理解上述大量數據,以下重點關注分析兩個特別有代表性的合約。
ETH Token轉账合約:在回放 ETH 歷史交易數據時,五個系統的絕對吞吐量和可擴展性比率均較 ERC20 實驗有所下降。這是因爲歷史交易中重復的地址導致了狀態爭用(讀寫衝突或寫寫衝突),從而阻礙了這些交易在並行 EVM 中的並發執行。
Voting 合約:Sei 合約幾乎只能按順序執行,在運行多個 EVM 時沒有速度提升。如果算法沒有轉變爲並行算法,其他系統也會出現類似的結果。對於 Aptos 和 Sui 的並行實現,必須爲「proposal」變量的臨時結果在不同地址初始化多個資源。此外,並行實現還必須基於投票者的地址提供手動調度,將投票者的交易引導至不同的虛擬機,並訪問臨時結果以進行並行執行。
由實驗結果得到的啓發
從實驗結果中我們得到了以下啓示:
對比樂觀與悲觀並行方法
Aptos 和 Sui 在不同的特定場景中各有其最佳表現。在 ERC20 轉账案例中,Aptos 表現優於 Sui,這是因爲 ERC20 轉账的每筆交易中使用隨機生成的地址,導致衝突非常少。相反,在 ETH 測試案例中,由於回放 ETH 歷史交易帶來的大量衝突,Sui 的表現優於 Aptos。
Aptos 執行中的時間分析
下表展示了在運行這 2 個合約時 Aptos 的性能分析數據(使用相同的智能合約,但交易數據分別採用的隨機生成或歷史交易數據)。由於性能分析十分耗時,測試所用的並行虛擬機數量最多限制在 64 個。
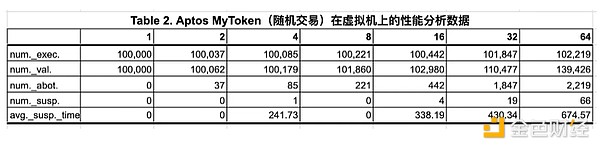
Aptos 交易執行包括執行和驗證兩個步驟,測試數據顯示其中大量的交易執行狀態被標記爲「SUSPEND」(掛起),且這些交易執行耗時很長。「SUSPEND」意味着交易執行暫停,直到其狀態依賴關系得到解決才可以恢復執行。對於 64個虛擬機上的隨機交易,執行和驗證的總次數分別爲 102,219 次和 139,426 次。而對於歷史交易,這些數字增加到 186,948 次和 667,148 次,交易掛起次數從 66 次增加到 46,913 次。因此,當交易執行中發生大量狀態衝突時,回滾成爲樂觀並行化的沉重負擔。
Sui 執行中的時間分析
以下圖表展示了 Sui 在 ETH Token 轉账合約測試和 Voting 合約測試中的耗時明細。在 Sui 的並行執行引擎中,有三個主要步驟:(1) 排隊時間:交易被事務管理器選中之前的等待時間;(2) 任務管理時間:交易被放入 Sui 的 Executing Txns 哈希圖或 Pending Txns 哈希圖,到它被 Sui 的 Execution Driver 接收之間的時間;(3) 函數執行時間:由 Execution Driver 中的工作线程執行合約函數的時間。
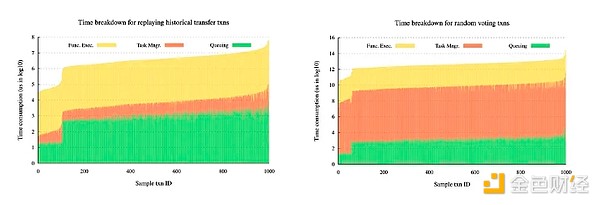
任務管理時間涉Locking和等待兩個部分。對比這兩個圖表可以看出,Voting測試中的任務管理時間佔整個執行時間的比例明顯比ETH Token轉账測試大得多。這是因爲在Voting測試中,訪問共享對象需要通過Locking和等待來避免衝突,使得任務管理時間比函數執行時間和排隊時間多了2到4個數量級。相比之下,在ETH Token轉账測試中,由於只使用了Owned Objects,繞過了並發控制,任務管理時間要少得多。
Aptos 和 Sui 的局限性
總結來說,Aptos 採用樂觀並行化,即使在存在衝突的情況下也允許並行交易執行。這種基於樂觀並發控制(OCC)的方法對以讀取爲主的工作負載非常有效,這在寫入請求稀少的數據庫和大數據系統中較爲常見。然而,在區塊鏈系統中,由於鏈上執行涉及的gas 費用,這種方法可能會產生巨大的 Gas 开銷。實際上,用戶通常將只讀請求(例如歷史交易或區塊查詢)發送到像 Etherscan 這樣的鏈下數據庫,而寫入請求則用於鏈上執行。在這種情況下,像 Aptos 這樣的 OCC 系統將頻繁遇到交易「Suspend」(中止)和掛起,從而降低並行虛擬機的整體性能。
相比之下,Sui 採用悲觀並行化,嚴格驗證交易之間的狀態依賴性,並通過 Locking 機制防止執行過程中的衝突。這種基於悲觀並發控制(PCC)的方法更適合計算密集型工作負載,在這種情況下,PCC相關的开銷甚至小到忽略不計。但在邏輯簡單的操作中,PCC 相關的开銷很容易成爲性能瓶頸。在現實世界裏,許多在區塊鏈系統上執行的交易,如 ERC20 Token 轉账、Move Token 轉账或 NFT 轉账,都涉及相對簡單的操作。具體來說,ERC20 代幣轉账通常涉及從一個地址減去一定金額並將其加到另一個地址。類似地,Move Token 轉账或 NFT 轉账涉及將一個資源或對象從一個地址移動到另一個地址。即使要考慮所有權驗證等額外檢查, 這些操作也非常快速。此時,PCC 的相關开銷就會成爲並行系統性能的限制因素。
爲了解決這些挑战,PREDA 提出了一個幾乎完全避免 PCC 开銷和 OCC 重新執行需求的系統。該方法通過高效地拆分鏈上狀態實現幾乎無衝突的並行執行。
Crystality 和 PREDA 的性能表現
在所有合約測試中,Crystality 和 PREDA 的性能數據都顯著優於 Sei、Aptos 和 Sui,其中 PREDA 表現尤爲突出,因爲它以原生二進制模式而非 WASM 進行執行。這種高性能得益於幾乎無衝突的並行執行。PREDA 從設計之初就考慮了以下2個關鍵環節:
定義不同的合約狀態範圍,系統將依據這個範圍進行狀態拆分和維護。
要實現交易的執行流從一個虛擬機到另一個虛擬機的切換。
PREDA 的核心在於引入了可編程作用域(Programmable Contract Scopes),將合約狀態拆分爲不重疊、可並行的細粒度片段;並引入了異步函數接力(Asynchronous Functional Relay),用於描述不同 EVM 之間的執行流切換。
我們來進一步解釋這些概念的含義,在 PREDA 中,一個合約函數被分解爲多個有序步驟,每個步驟依賴於單一的、可並行的狀態片段,且不產生衝突。
舉個例子:通常情況下,Token 轉账涉及兩個步驟:一是提取步驟,即訪問Sender的狀態並提取指定數量的 Token 的,二是存入步驟,即訪問 Recipient 的狀態並存入相應數量的 Token。像 Sei、Aptos 和 Sui 等實現的最新並行機制,試圖同步執行每個交易中的所有步驟。如果兩個交易之間的訪問狀態是共享的或被更新的,比如當 Sender 或 Recipient 相同時,這兩個交易將無法並行執行。
然而,PREDA 採用了一種可拆分且異步的機制,其中交易的各個步驟根據其數據訪問依賴性進行分解,使每個步驟能夠獨立於其他步驟異步執行。對相同狀態的訪問嚴格按照原始交易塊中確定的順序進行序列化,並由共識算法保證,即由區塊創建者排序。
例如,Token轉账交易 Txn 0(將代幣從地址狀態 A 轉移到狀態 B)和 Txn 1(從狀態 A 轉移到狀態 C)可以按照順序兩次訪問 A(分別用於 Txn 0 和 Txn 1),然後並行訪問 B 和 C。
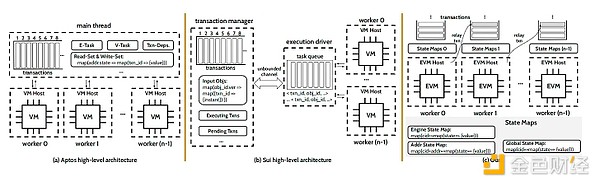
Aptos,Sei 和 PREDA 中並行執行的架構比較
PREDA 和 Crystality 的局限性
盡管 PREDA 和 Crystality 能爲區塊鏈系統賦能, 提供顯著的性能優勢,但它們的局限性也體現在如下方面。
並行 EVM 之間工作負載不均衡
Crystality 的數據拆分和執行流重定向機制可能會導致並行 EVM 在運行時出現負載不均衡的問題。我們在用 MyToken 合約重放歷史 ETH Token轉账交易時觀察到了這一問題。
爲了評估負載分布情況,我們統計了每個 EVM 上執行的交易數量,包括原始交易和接力交易,然後計算了這些數量的極差和標准差。結果顯示,在 64 個 EVM 上執行的交易數量極差與 2 個 EVM 上的範圍相當,這意味着在某些EVM地址存在熱點問題(即歷史交易集中發生在一部分地址上)。對 ETH 數據集的進一步調查發現,每一個熱點地址涉及高達 4000 多筆交易。這裏必須指出的是,據我們了解,Aptos 和 Sui 在這種情況下,也無法做並行化執行。
我們的測試數據表明,隨着 EVM 數量的增加,標准差有所降低,這意味着增加更多的 EVM 有助於緩解負載不平衡問題。
爲了解決區塊鏈上的熱點問題,一個可行的解決方案是使用多個地址而不是單個地址來發送或接收代幣。如果負載不均衡是由於幾個非熱點地址映射到同一虛擬機造成的,那么分片(Sharding)區塊鏈中的現有方法,例如數據遷移,可能會有所幫助。
程序重寫
PREDA 和 Crystality 的另一個顯著的局限性是,开發者需要使用 directives 重寫智能合約。如果有一種工具可以自動將 Solidity、Move 或 Rust 編寫的現有智能合約翻譯爲等效的 Crystality 智能合約,將大大優化开發者的體驗。從前人經驗看來,也並不難實現,已經有一些研究探索了不同語言之間的翻譯,例如從 Solidity 到 Move 和從 Python 到 Solidity。
自然語言處理的技術進步,大大增強了自動代碼生成的潛力。這些進展結合基於規則和模式的編譯器翻譯技術(如用於大數據的 SQL 到 MapReduce 翻譯和用於深度學習的計算圖到矩陣計算的翻譯)完全可以爲开發自動化的智能合約翻譯工具, 提供助力。
結論
Sei、Aptos、Sui 與 Crystality/PREDA 之間的性能對比突顯了區塊鏈並行化領域的不斷演變。Aptos(與 Sei)和 Sui 分別展示了樂觀並行化和悲觀並行化機制的潛力,各自在不同場景下展現了優勢。然而,Crystality 和 PREDA 顯著的性能提升表明,更先進的並行化模型可能是解鎖更高層級的可擴展性和效率的關鍵。
爲了總結我們對區塊鏈領域三種主要並行化方法的探索和觀察,我們整理匯總了一張表格。如果您想從這篇文章中獲得一份Takeaway,那就是本表格中的內容。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:並行執行區塊鏈系統調研
地址:https://www.sgitmedia.com/article/39940.html
相關閱讀:
- 香港穩定幣最新法案 創新催化劑還是監管枷鎖? 2024-12-23
- Ethena 對 DeFi 來說是系統性風險還是救世主? 2024-12-23
- Outlier:以太坊六大L2激勵效果研究 爲何新L2空投後留不住用戶 2024-12-23
- 韓國加密貨幣之王的稅務困局:Do Kwon被追繳千億稅款始末 2024-12-23
- 歷史新高?貝萊德BTC ETF流出7300萬美元 2024-12-23
- 2025年有哪些值得期待的加密股票? 2024-12-23
- 特朗普任命前大學橄欖球運動員Bo Hines爲加密貨幣委員會主席 2024-12-23
- 金色百科 | 什么是壓縮NFT? 如何鑄造 cNFT? 2024-12-23
