Arweave第17版白皮書解讀(四):存儲完整數據副本才是王道
2024-04-01 12:55 金色精選
作者:Gerry Wang @ Arweave Oasis,原文首發於 @ArweaveOasis 推特
在解讀(三)文中,我們通過數學推導對 #SPoRes 的可行性進行了論證。文中的 Bob 與 Alice 一起參與了這場證明遊戲。那在 #Arweave 挖礦中,協議部署了這個 SPoRes 遊戲的修改版本。在挖礦過程中,協議充當了 Bob 的角色,而網絡中的所有礦工共同扮演 Alice 的角色。SPoRes 遊戲的每個有效證明都用於創建 Arweave 的下一個區塊。具體說來,Arweave 區塊的產生與以下參數相關:
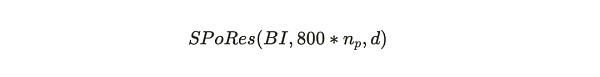
其中:
BI = Arweave 網絡的區塊索引 Block Index;
800*n_p = 每個檢查點每個分區最多解鎖 800 個哈希次數,n_p 是礦工存儲的大小爲 3.6 TB 的分區的數量,兩者相乘是該礦工每秒最大可以嘗試的哈希運算次數。
d = 網絡的難度。
一個成功有效的證明是那些大於難度值的證明,而這個難度值會隨時間變化而被調整,以確保平均每 120 秒挖出一個區塊。如果區塊 i 與區塊(i+10)之間的時間差爲 t ,那么從舊難度 d_i 到新難度 d_{i+10} 的調整如下計算:
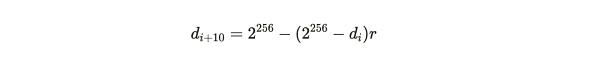
其中:
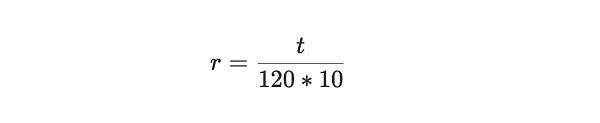
公式注解:從上面兩個公式中可以看出, 網絡難度的調整主要靠參數 r,而 r 意味着實際的區塊產生所需要的時間相對於系統期望的 120 秒一個區塊的標准時間的偏移參數。
新計算的難度決定了基於每個生成的 SPoA 證明,挖掘區塊成功的概率,具體如下:

公式注解:經過以上推導可以得到新難度下的挖掘成功概率是舊難度下成功概率乘以參數 r。
同樣,VDF 的難度也會重新計算,目的是爲了保持檢查點周期在時間上能夠每秒發生一次。
完整副本的激勵機制
Arweave 通過 SPoRes 機制來生成每個區塊是基於這樣一個假設:
在激勵下,無論是個體礦工還是群體合作礦工,都會以維護完整數據副本作爲挖礦的最佳策略來執行。
在先前介紹的 SPoRes 遊戲中,存儲數據集的同一部分的兩個副本所釋放的 SPoA 哈希數量與存儲整個數據集的完整副本是相同的,這就給礦工留下了投機行爲的可能。於是 Arweave 在實際部署這套機制的時候,對其作了一些修改,協議通過將每秒解鎖的 SPoA 挑战數量分成兩部分:
一部分在礦工存儲的分區中指定一個分區來釋放一定數量的 SPoA 挑战;
另一部分則是在 Arweave 所有數據分區中隨機指定一個分區來釋放 SPoA 挑战,如果礦工沒有存儲這個分區的副本,則會失去這一部分的挑战數量。
這裏也許你會覺得有些疑惑,SPoA 與 SPoRes 之間究竟是什么關系。共識機制是 SPoRes,爲什么釋放的卻是 SPoA 的挑战?其實它們之間是一種從屬的關系。SPoRes 是這個共識機制的總稱,其中包含了需要礦工做的一系列 SPoA 證明挑战。
爲了理解這一點,我們將檢查前一節中描述的 VDF 是如何被用來解鎖 SPoA 挑战的。

以上代碼詳細表述了如何通過 VDF(加密時鐘)來解鎖存儲分區中由一定 SPoA 數量組成的回溯範圍的過程。
大約每秒鐘,VDF 哈希鏈會輸出一個檢查點(Check);
這個檢查點 Check 將與挖礦地址(addr),分區索引(index(p)),和原始 VDF 種子(seed)一起用 RandomX 算法計算出一個哈希值 H0,該哈希值是一個 256 位的數字;
C1 是回溯偏移量,它是由 H0 除以分區的大小 size(p) 而產生一個余數得來,它將是第一個回溯範圍的起始偏移量;
從這個起始偏移量开始的連續 100 MB 範圍內的 400 個 256 KB 的數據塊,就是被解鎖出來的第一回溯範圍 SPoA 挑战。
C2 是第二回溯範圍的起始偏移量,它是由 H0 除以所有分區大小之和而產生的余數得來的,它同樣也解鎖了第二回溯範圍的 400 個 SPoA 挑战。
這些挑战的約束是第二範圍內的 SPoA 挑战需要在第一個範圍的對應位置也有 SPoA 挑战。
每個已打包分區的性能
每個已打包分區的性能指的是每個分區在每個 VDF 檢查點所產生的 SPoA 挑战數量。當礦工存儲的是分區唯一副本 Unique Replicas 時,SPoA 挑战數量將大於礦工存儲相同數據的多個備份 Copies 時的數量。
這裏的「唯一副本」概念與「備份」概念是有極大區別的,具體可以閱讀過去的文章《Arweave 2.6 也許更符合中本聰的愿景》的內容。
如果礦工只存了分區的唯一副本數據,那每個打包過的分區將會產生所有第一回溯範圍的挑战,然後根據存儲分區副本的數量產生落在該分區內的第二回溯範圍。若整個 Arweave 編織網絡中共有 m 個分區,礦工存儲了其中 n個分區的唯一副本,那么每個打包分區的性能爲:
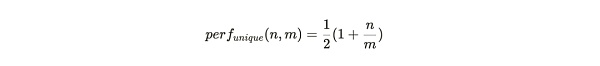
當礦工存儲的分區是相同數據的備份時,每個打包過的分區仍然會產生所有第一回溯範圍挑战。但只有在 1/m 次情況下,第二回溯範圍會位於這個分區內。這便給這種存儲策略行爲帶來了一個顯著的性能懲罰,產生 SPoA 挑战數量的比率僅爲:
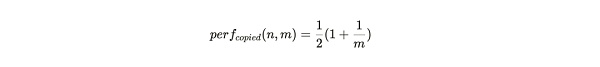
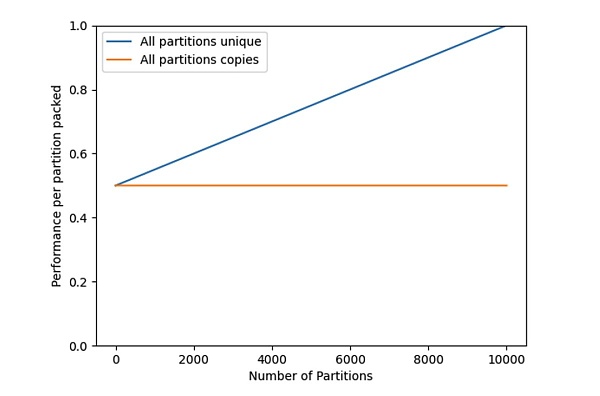
圖 1:當一個礦工(或一組合作的礦工)完成打包他們的數據集時,給定分區的性能會提高。
圖 1 中的藍色线爲存儲分區唯一副本的性能 perf_{unique}(n,m) ,該圖直觀地表明了,當礦工只存儲了很少的分區副本時,每個分區的挖礦效率僅爲 50%。當存儲和維護所有數據集部分,即 n=m 時,挖礦效率達到最大化的 1。
總哈希率
總哈希率(見圖 2 所示)由以下方程給出,通過將每個分區(per partition)的值乘以 n 得到:
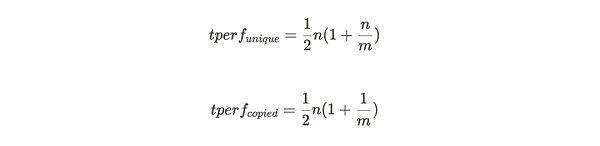
以上公式表明了隨着編織網絡(Weave)大小的增長,如果不存儲唯一副本數據,懲罰函數(Penalty Function)隨着存儲分區數量的增加而呈二次方增長。
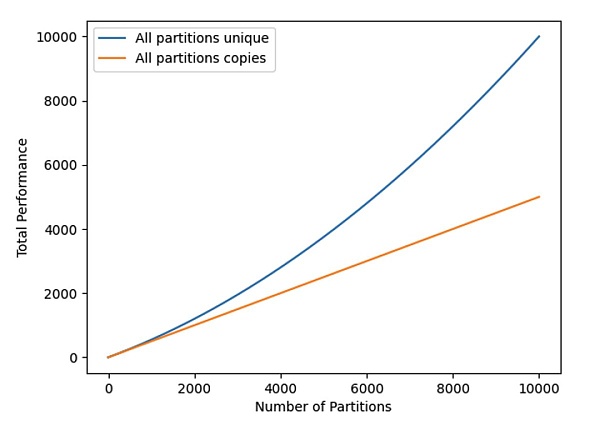
圖 2:唯一數據集和備份數據集的總挖礦哈希率
邊際分區效率
基於這個框架,我們來探討礦工在添加新分區時面臨的決策問題,即是選擇復制一個他們已有的分區,還是從其他礦工那獲取新數據並打包成唯一副本。當他們從最大可能的 m 個分區中已經存儲了 n 個分區的唯一副本時,他們的挖礦哈希率是成比例的:
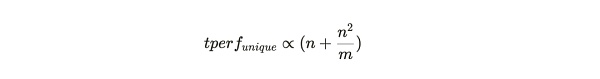
所以增加一個新分區的唯一副本,其額外收益爲:
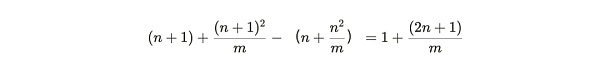
而復制一個已打包分區的(更小的)收益是:
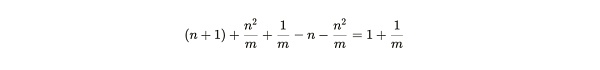
將第一個數量除以第二個數量,我們得到礦工的相對邊際分區效率(relative marginal partition efficiency) :
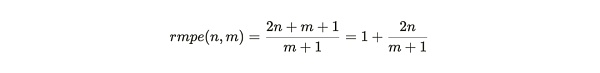
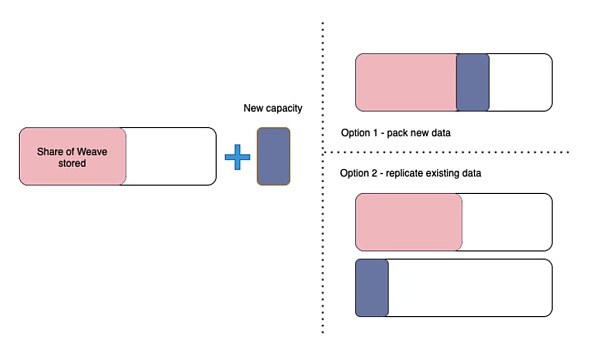
圖 3:礦工被激勵去構建成一個完整的副本(選項 1),而不是制作他們已經擁有的數據的額外副本(選項 2)
rmpe 值可被視爲礦工在添加新數據時復制現有分區的一種懲罰。在這個表達式中,我們可以將 m 趨向無窮大來處理,然後再考慮不同 n 值下的效率權衡:
當礦工擁有接近完整數據集副本時,完成一個副本的獎勵最高。因爲如果 n 趨近於 m 並且 m 趨向於無窮大,則 rmpe 的值就爲 3。這意味着,接近完整副本時,尋找新數據的效率是重新打包現有數據效率的 3 倍。
當礦工存儲一半編織網絡(Weave)時,例如,當 n= 1/2 m, rmpe 是 2。這表示尋找新數據的礦工收益是復制現有數據收益的 2 倍。
對於較低的 n 值,rmpe 值趨向於但總是大於 1。這意味着存儲唯一副本的收益永遠都是大於復制現有數據的收益。
隨着網絡的增長(m 趨向無窮大),礦工構建成完整副本的動力將會增強。這促進了合作挖礦小組的創建,這些小組共同存儲至少一個數據集的完整副本。
本文主要介紹了 Arweave 共識協議構建的細節,當然這也只是這部分核心內容的开篇。從機制介紹與代碼中,我們可以非常直觀地了解到協議的具體細節。希望能夠幫助大家理解。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:Arweave第17版白皮書解讀(四):存儲完整數據副本才是王道
地址:https://www.sgitmedia.com/article/27129.html
相關閱讀:
- 香港穩定幣最新法案 創新催化劑還是監管枷鎖? 2024-12-23
- Ethena 對 DeFi 來說是系統性風險還是救世主? 2024-12-23
- Outlier:以太坊六大L2激勵效果研究 爲何新L2空投後留不住用戶 2024-12-23
- 韓國加密貨幣之王的稅務困局:Do Kwon被追繳千億稅款始末 2024-12-23
- 歷史新高?貝萊德BTC ETF流出7300萬美元 2024-12-23
- 2025年有哪些值得期待的加密股票? 2024-12-23
- 特朗普任命前大學橄欖球運動員Bo Hines爲加密貨幣委員會主席 2024-12-23
- 金色百科 | 什么是壓縮NFT? 如何鑄造 cNFT? 2024-12-23
