OpenAI 困於“遙遙領先”
2023-11-30 10:45 遠川科技評論
來源:遠川科技評論
轟動全球的大型連續劇“奧特曼去哪兒”劃上了句號,但OpenAI的煩心事並沒有結束。
Sam Altman能在短時間內官復原職,離不开微軟忙前忙後。今年以來,微軟一直在幫助好兄弟做大做強。不僅追加投資了100億美金,還大規模調用了微軟研究院的人力,要求放下手頭的基礎科研項目,全力將GPT-4等基礎大模型落地成產品,用OpenAI武裝到牙齒。
但很多人不知道的是,今年9月,微軟研究院負責人Peter Lee曾接到過一個祕密項目——打造OpenAI的替代品。
第一個“去OpenAI化”的,正是微軟的首個大模型應用Bing Chat。
據The Information爆料,微軟正嘗試將原本集成在Bing當中的OpenAI大模型,逐步替換成自研版本。11月的Ignite开發者大會上,微軟宣布Bing Chat更名爲Copilot,如今市場定位與ChatGPT頗爲相似——很難不讓人多想。
全新的Copilot
不過,微軟的初衷並不是OpenAI的技術能力有瑕疵,也不是預見到了OpenAI管理層的分歧,真實原因有點讓人哭笑不得:
因爲OpenAI的技術能力太強了。
开着蘭博基尼送外賣
促使微軟自研大模型的契機,是OpenAI的一次失敗。
ChatGPT轟動全球之際,OpenAI的計算機科學家們正在忙於一個代號爲Arrakis的項目,希望對標GPT-4打造一個稀疏模型(sparse model)。
這是一種特殊的超大模型:處理任務時,模型只有特定部分會被激活。例如當用戶需要生成一段摘要時,模型會自動激活最適合該工作的部分,不必每次都調動整個大模型。
相較於傳統的大模型,稀疏模型擁有更快的響應速度和更高的准確性。更重要的是它可以大大降低推理的成本。
翻譯成人話就是,殺雞再也不用牛刀了——而這正是微軟所看重的。

谷歌對稀疏模型優勢的總結
輿論聊到大模型成本時,總愛談論7、8位數的訓練成本,以及天文數字的GPU开支。但對大多數科技公司而言,模型訓練和數據中心建設只是一次性的資本开支,一咬牙並非接受不了。相比之下,日常運行所需的昂貴推理成本,才是阻止科技公司進一步深入的第一道門檻。
因爲在通常情況下,大模型並不像互聯網那般具備明顯的規模效應。
用戶的每一個查詢都需要進行新的推理計算。這意味着使用產品的用戶越多、越重度,科技公司的算力成本也會指數級上升。
此前,微軟基於GPT-4改造了大模型應用GitHub Copilot,用於輔助程序員寫代碼,收費10美元/月。
據《華爾街日報》的爆料,由於昂貴的推理成本,GitHub Copilot人均每月虧20美金,重度用戶甚至可以給微軟帶來每個月80美金的損失。

GitHub Copilot
大模型應用的入不敷出,才是推動微軟自研大模型的首要原因。
OpenAI的大模型在技術上依舊遙遙領先,長期位於各大榜單的首位,但代價是昂貴的使用成本。
有AI研究員做過一筆測算,理論上GPT-3.5的API價格,幾乎是开源模型Llama 2-70B推理成本的3-4倍,更別提全面升級後的GPT-4了。
然而除了代碼生成、解決復雜數學難題等少數場景,大部分工作其實完全可以交由參數較小的版本和开源模型。
初創公司Summarize.tech就是個活生生的案例。它的業務是提供總結音視頻內容的工具,擁有約20萬月活用戶,早期曾使用GPT-3.5來支持其服務。
後來,該企業試着將底層大模型更換成开源的Mistral-7B-Instruct,發現用戶並沒有感知到差異,但每月的推理成本卻從2000美元降低至不到1000美元。
也就是說,OpenAI爲客戶無差別提供動力強勁的蘭博基尼,但大部分客戶的業務其實是送外賣——這構成了OpenAI的“遙遙領先難題”。
所以不光是微軟,連Salesforce、Wix等OpenAI的早期大客戶,也已經替換成更便宜的技術方案。
降低推理成本,讓“开奧迪比雅迪更便宜”,成爲了OpenAI必須要解決的課題,這才有了前文提到的稀疏模型項目Arrakis。
事實上,不光是OpenAI,谷歌也在從事相關研究,並且已經取得了進展。8月的Hot Chips大會上,谷歌首席科學家、原谷歌大腦負責人傑夫·迪恩更在演講中提到,稀疏化會是未來十年最重要的趨勢之一。

傑夫·迪恩還發表過稀疏模型的論文
正是遙遙領先帶來的高成本讓微軟琢磨起了“自力更生”的可能性,OpenAI其實也注意到了這個問題:
11月6日的开發者大會上,OpenAI推出了GPT-4 Turbo,一口氣降價1/3,已低於Claude 2——即最大競爭對手Anthropic开發的閉源大模型。
OpenAI的“蘭博基尼”雖然還不夠便宜,至少比其他小轎車實惠了不少。
可惜11天之後,一場足以載入科技史的鬧劇,正使得這一努力大打折扣。據外媒爆料,在奧特曼與OpenAI董事會談判回歸的那個周末,已有超過100個客戶聯系了友商Anthropic。
商業化的悖論
即便沒有這場內亂,OpenAI的客戶流失危機可能依然存在。
這要從OpenAI的模型與產品設計思路講起:
不久前,OpenAI往开發者社群中投入了GPTs這顆重磅炸彈。用戶可以利用自然語言來定制不同功能的聊天機器人。截止至奧特曼復職當天,用戶已上傳了19000個功能迥異的GPTs聊天機器人,平均日產1000+,活躍程度堪比一個大型社區。

功能迥異的GPTs
衆所周知,GPT模型並不开源,而且還有“遙遙領先難題”。但對個人开發者和小型企業來說,OpenAI具備兩個开源模型所無法匹敵的優勢:
其一是开箱即用的低开發門檻。在海外論壇上,一些利用OpenAI基礎模型搞开發的小型團隊,會將自家產品形容爲“wrappers(包裝紙)”。因爲GPT模型強悍的通用能力,他們有時只需要替模型开發一個UI,再找到適用場景,就能拿到訂單。
开發者如果需要進一步微調模型,OpenAI同樣提供了一項名爲的LoRA(低秩自適應)的輕量級模型微調技術。
簡單來說,LoRA的大致原理是先將大模型“拆散”,再面向指定任務做適應性訓練,進而提升大模型在該任務下的能力。LoRA主要着眼於調整模型內部結構,並不需要太多行業數據進行微調。
但在定制开源模型時,开發者有時會使用全量微調。雖然在特定任務上表現更好,但全量微調需要更新預訓練大模型的每一個參數,對數據量要求極高。
相比之下,OpenAI模式顯然對普通开發者更加友好。
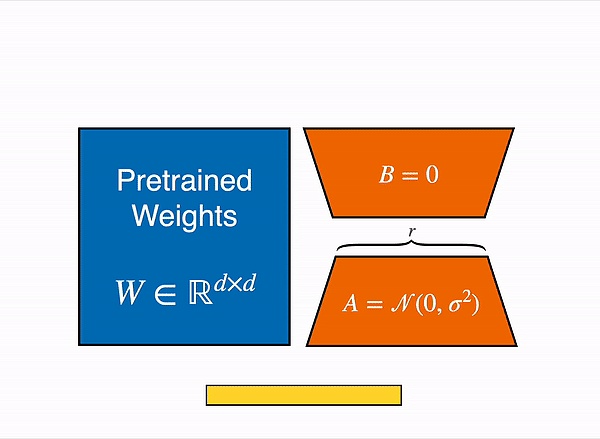
LoRA原理示意圖
其次,前文曾提到大模型並不具備規模效應,但這句話其實有一個前提——即計算請求充足的情況下。
測試顯示,每批次發送給服務器的計算請求越少,對算力的利用效率會降低,進而會導致單次計算的平均成本直线上升。
OpenAI可以一次性將所有客戶的數百萬個計算請求一起捆綁發送,但個人开發者和中小企業卻很難做到這一點,因爲並沒有那么多活躍用戶。
簡單來說就像送快遞,同樣從上海到北京,OpenAI客戶多,可以一次送100件;其他模型就湊不出這么多了。
咨詢公司Omdia的分析師曾評價稱,OpenAI從規模效應中的獲利,遠遠超過大多數在AWS或Azure上托管小型开源模型的初創企業。
所以,雖然“ChatGPT一更新就消滅一群小公司”的現象客觀存在,但還是有不少开發者愿意賭一把。
PDF.ai的創始人Damon Chen就是直接受害者,PDF.ai的主要功能是讓模型閱讀PDF文件,結果10月底ChatGPT也更新了這項能力。但Damon Chen卻非常淡然:“我們的使命不是成爲另一家獨角獸,幾百萬美金的年收入已經足夠了”。
但對於富可敵國的大公司來說,OpenAI的這些優勢全都成了劣勢。
比如,OpenAI在輕量級开發上頗有優勢,但隨着企業不斷深入場景,需要進一步定制時,很快會又一次面臨“遙遙領先難題”:
由於GPT-4過於復雜且龐大,深度定制需要耗費最低200萬美金和數月的开發時間。相比之下,全量微調开源模型的成本多爲數十萬美元上下,兩者明顯不是一個量級。
另外,微軟、Salesforce等大客戶自己的計算請求就夠多了,根本不需要和別人一起拼單降成本,這讓OpenAI在成本端優勢全無。即便是初創企業,隨着用戶不斷增加,使用OpenAI模型的性價比也會降低。
前文提到擁有20萬月活的初創公司Summarize.tech,就成功利用开源的Mistral-7B-Instruct降本50%以上。
要知道7B參數的小型开源模型還可以運行在“老古董”級的英偉達V100上——該GPU發布於2017年,甚至沒進美國芯片出口管制名單的法眼。
Summarize.tech
從商業角度看,能夠支撐公司營收的恰恰是財大氣粗的大公司,如何抓住那些“野心不止數年收入百萬美金”的客戶,已是OpenAI必須面對的命題。
閃點事件
讓OpenAI“面對商業化問題”聽上去似乎有些奇怪,畢竟直到2023年初,跟賺錢相關的議題還遠不在OpenAI的日程表上,更別提搞什么开發者大會了。
今年3月,OpenAI總裁布羅克曼(Greg Brockman)——也就是上周和奧特曼一起被开除的大哥——接受了一次採訪。他坦誠地說道,OpenAI並沒有真正考慮過構建通用的工具或者垂直領域的大模型應用。雖然嘗試過,但這並不符合OpenAI的DNA,他們的心也不在那裏。
持續四天半的鬧劇之後,Brockman也再度回歸
這裏的DNA,其實指的是一種純粹理想主義、保護人類免受超級智能威脅的科學家文化。畢竟OpenAI的立身之本很大程度上建立在2015年馬斯克與奧特曼的“共同宣言”——AI更安全的道路將掌控在不受利潤動機污染的研究機構手中”。
理想主義大旗的號召下,OpenAI成功招募到了以伊利亞(Ilya Sutskever)爲首的頂尖科學家團隊——盡管當時奧特曼提供給他們的薪資還不足谷歌一半。
讓OpenAI开始轉變的一個關鍵因素,恰恰是ChatGPT的發布。
最初,OpenAI領導並沒有將ChatGPT視作一款商業化的產品,而是將其稱爲一次“低調的研究預覽”,目的是收集普通人與人工智能交互的數據,爲日後GPT-4的开發提供助力。換句話說,ChatGPT能火成這樣,是OpenAI沒有想到的。
出乎意料的爆紅改變了一切,也促使奧特曼和布羅克曼轉向了加速主義。
所謂加速主義,可以簡單理解爲對AGI的商業化抱有無限熱情,准備大幹快上跑步進入第四次工業革命。與之對應的則是安全主義,主張用謹慎的態度來發展AI,時刻衡量AI對人類的威脅。
一位匿名OpenAI員工在接受《大西洋月刊》採訪時說道,“ChatGPT之後,收入和利潤都有了明確的路徑。你再也無法爲‘理想主義研究實驗室’的身份做辯護了。那裏有客戶正等着服務。”

ChatGPT也催生了“科技界最好的兄弟情誼”
這種轉變讓OpenAI开始踏入一個陌生的領域——持續將研發成果轉換成受歡迎的產品。
對一家曾以理想主義標榜的象牙塔來說,這項工作顯然有些過於“接地氣”了。比如技術領袖伊利亞就是個計算機科學家而非產品經理,之前在谷歌也多負責理論研究,產品落地的職責在傑夫·迪恩領導的谷歌大腦團隊身上。
在ChatGPT發布前,OpenAI更像是幾個財富自由的科學家和工程師組成的小作坊,但時過境遷,他們變成了一個正兒八經的商業機構。
過去一年,OpenAI新增了數百位新僱員,用於加速商業化。根據The Information的報道,OpenAI的員工總數很可能已經超過700人。就算不考慮賺錢,也得有方法應對運營成本——畢竟科學家也要還房貸啊。
短暫又劇烈的“奧特曼去哪兒”事件並沒有解決這個問題,反而讓它變得愈發尖銳:OpenAI到底是個什么組織?
在CNBC的一次採訪裏,馬斯克曾這樣形容由他親手創辦、後來又將他掃地出門的公司:“我們成立了一個組織來拯救亞馬遜雨林,但後來它卻做起了木材生意,砍伐了森林將其出售。”
這種矛盾使得OpenAI困於遙遙領先,也催生了這場驚呆所有人下巴的鬧劇。
今年早些時候,連线雜志的記者曾跟訪了奧特曼一段時間,期間也曾反復提及這個問題,但奧特曼每次都堅稱,“我們的使命沒有改變”。但當信奉安全主義的伊利亞滑跪,以及奧特曼回歸,顯然OpenAI已經做出了它的選擇。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:OpenAI 困於“遙遙領先”
地址:https://www.sgitmedia.com/article/16799.html
相關閱讀:
- IntoTheBlock 聯創:Web3基礎設施正在被過度建造 我們正在盲目行事 2024-12-20
- 國際清算銀行最新提出的央行數字貨幣框架究竟是什么? 2024-12-20
- SOL 質押完整指南:從機制和收益等方面解析 Solana 質押生態 2024-12-20
- 特朗普正式獲得總統職位 BTC儲備競賽即將开啓 2024-12-20
- 預防量子計算威脅實用指南 2024-12-20
- 特朗普兩年時間通過加密貨幣賺了多少錢? 2024-12-20
- Chainalysis:朝鮮黑客從加密平台竊取的錢都幹什么了? 2024-12-20
- 估值45億美元,OpenAI和谷歌大佬聯手創立的AI Agent公司爲何這么牛? 2024-12-20

