谷歌新Gemini AI模型在基准測試中擊敗GPT-4o
2024-08-02 09:55 金色精選
作者:Tristan Greene,CoinTelegraph;編譯:陶朱,金色財經
生成式人工智能基准測試領域又出現了一位新霸主,它的名字是 Gemini 1.5 Pro。
之前的冠軍 OpenAI 的 ChatGPT-4o 終於在 8 月 1 日被超越,當時谷歌悄然發布了其最新模型的實驗版本。
Gemini 的最新更新沒有大張旗鼓地發布,目前被標記爲實驗性的。但它很快引起了社交媒體上人工智能社區的關注,因爲有報道稱它在基准測試分數上超越了競爭對手。
人工智能基准
自 GPT-3 發布以來,OpenAI 的 ChatGPT 一直是生成式 AI 的標杆。過去一年左右,其最新模型 GPT-4o 和最接近的競爭對手 Anthropic 的 Claude-3 在大多數常見基准測試中都遙遙領先於大多數其他模型,幾乎沒有遇到任何競爭對手。
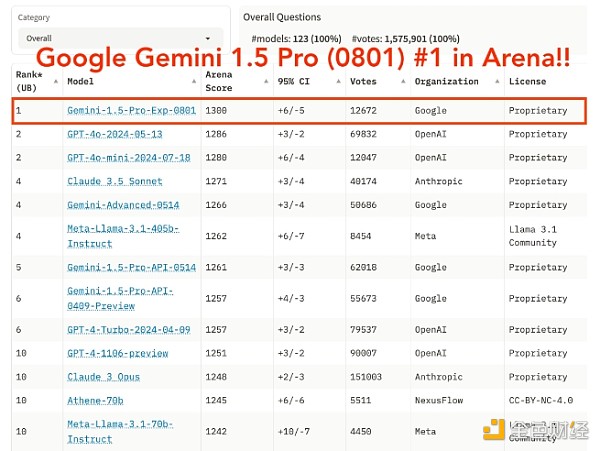
來源:大型模型系統組織。
最受歡迎的基准測試之一是 LMSYS Chatbot Arena。它測試各種任務的模型並分配總體能力分數。GPT-4o 的得分爲 1,286,而 Claude-3 獲得了可觀的 1,271 分。
Gemini 1.5 Pro 的先前版本得分爲 1,261。但 8 月 1 日發布的實驗版本 (Gemini 1.5 Pro 0801) 得分高達 1,300。
這表明它總體上比競爭對手更強大,但基准測試並不一定能准確反映 AI 模型能做什么和不能做什么。
社區興奮
在沒有更深入的比較的情況下,我們正進入一個 AI 聊天機器人市場已經足夠成熟,可以提供多種選擇的時代。最終由用戶來決定哪種 AI 模型最適合他們。
據傳,Gemini 的最新版本引起了一波興奮,社交媒體上的用戶稱它“非常好”。一位 Redditor 甚至寫道,它“完全勝過 4o”。
目前尚不清楚 Gemini 1.5 Pro 的實驗版本是否會成爲未來的默認版本。雖然截至本文發表時,它仍然普遍可用,但它處於早期發布或測試階段這一事實表明,出於安全或協調原因,該模型可能會被撤銷或更改。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:谷歌新Gemini AI模型在基准測試中擊敗GPT-4o
地址:https://www.sgitmedia.com/article/37302.html
相關閱讀:
- 如何預防丟幣? 2024-12-25
- Coingecko:2024 年最流行的加密敘事是什么? 2024-12-25
- Blockworks:2025年加密領域將有哪五大變化? 2024-12-25
- 虛擬貨幣推廣返傭有哪些風險? 2024-12-25
- 加密時代的職務犯罪:北京億元涉幣職務侵佔案 追贓8900萬 2024-12-25
- MV Global報告:DeSci有望在2025年借助MEME迎來爆發式增長 2024-12-25
- 大陸資本加速布局 香港新增4家虛擬資產平台 發牌提速引關注 2024-12-25
- Raiinmaker創始人:亞太地區的Web3和人工智能夢想能實現嗎? 2024-12-25

