Meta計劃7月發布Llama 3大模型 小扎是怎么放狠話的?
2024-03-01 12:22 元宇宙之心
 免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
Meta計劃7月發布Llama 3大模型 小扎是怎么放狠話的?

 元宇宙之心
企業專欄
剛剛
元宇宙之心
企業專欄
剛剛
 關注
關注
來源:元宇宙之心
2月28日路透社報道,Meta計劃在7月份發布其最新版本的人工智能大型語言模型Llama 3,該模型將對用戶提出的有爭議的問題做出更好的回答。
Meta公司的研究人員正試圖升級該模型,使其能夠對存在爭議的問題提供相關聯的解答。
在競爭對手谷歌推出Gemini後,Meta暫停了圖像生成功能,因爲該功能生成的歷史圖像有時並不准確。

Meta的Llama 2爲其社交媒體平台上的聊天機器人提供支持,但根據相關的測試,它拒絕回答一些爭議性較小的問題,例如如何惡作劇朋友、如何贏得战爭或怎樣“殺死”汽車發動機。
然而,Llama 3能夠回答“如何關閉汽車發動機”等問題,這意味着它能夠理解用戶想要問的是如何關閉車輛而不是真的“殺死”發動機。
報道稱,Meta公司還計劃在未來幾周內任命一名內部人員,負責監督語氣和安全培訓,以努力使模型的反應更加細致入微。
01.Llama 3何時發布?
其實早在今年1月份,Meta首席執行官扎克伯格(Zuckerberg)就在ins視頻中宣布,Meta AI最近已开始訓練Llama 3。這是LLaMa系列大型語言模型的最新一代,此前,2023年2月發布了Llama 1模型(最初文體爲 “LLaMA”),7月發布了Llama 2模型。
雖然具體細節(如模型大小或多模態功能)尚未公布,但扎克伯格表示Meta打算繼續开源Llama基礎模型。

值得注意的是,Llama 1花了三個月的時間進行訓練,Llama 2花了大約六個月的時間進行訓練。如果下一代模型遵循類似的時間表,它們將於今年7月左右發布。
但Meta公司也有可能分配額外的時間進行微調,以確保模型的正確排列。
隨着开源模型越來越強大和生成式人工智能模型的應用愈加廣泛,我們需要更加謹慎,以降低模型被不良行爲者用於惡意目的的風險。扎克伯格在發布視頻中重申了Meta對模型進行“負責任、安全訓練”的承諾。
02.會开源嗎?
扎克伯格在隨後的新聞發布會上也重申了Meta對开放許可和實現AI民主化的承諾。他在接受《The Verge》採訪時說:“我傾向於認爲,這裏最大的挑战之一是,如果你打造的東西真的很有價值,那么它最終會變得非常集中和狹隘。如果你讓它更加开放,那么就能解決機會和價值不平等可能帶來的大量問題。因此,這是整個开源愿景的重要組成部分。”
03.會實現通用人工智能(AGI)嗎?
扎克伯格在發布視頻中也強調了Meta構建AGI(人工通用智能)的長期目標,AGI是人工智能的一個理論發展階段,在這一階段,模型將展現出與人類智能相當或優於人類智能的整體表現。
扎克伯格也表示:“下一代服務需要構建全面的通用智能,這一點已經變得越來越清晰。打造最好的人工智能助手、爲創作者服務的人工智能、爲企業服務的人工智能等等,這都需要人工智能各個領域的進步,包括從推理、規劃、編碼到記憶和其他認知能力。”
從扎克伯格的發言中我們可以看出,Llama 3模型並不一定意味着AGI將會實現,但Meta公司正在有意識地以可能實現AGI的方式來進行LLM开發和其它AI研究。
04.會是多模態嗎?
人工智能領域的另一個新興趨勢是多模態人工智能,也就是能夠理解和處理不同數據格式(或模態)的模型。
例如谷歌的Gemini、OpenAI的GPT-4V以及LLaVa、Adept或Qwen-VL等开源模型,可以在計算機視覺和自然語言處理(NLP)任務之間無縫切換,而不是开發單獨的模型來處理文本、代碼、音頻、圖像甚至視頻數據。
雖然扎克伯格已經確認,Llama 3和Llama 2一樣,將包括代碼生成功能,但他沒有明確談到其他多模態功能。
不過,扎克伯格確實在Llama 3發布視頻中討論了他如何設想人工智能與Metaverse(元宇宙)的交集:“Meta的Ray-Ban智能眼鏡是讓人工智能看你所看,聽你所聽的理想外形,它可以隨時提供幫助。”

這似乎意味着,無論是在即將發布的Llama 3版本中,還是在後續版本中,Meta對Llama模型的計劃都包括將視覺和音頻數據與LLM已經處理的文本和代碼數據整合在一起。
這似乎也是追求AGI的自然發展。
扎克伯格在接受《The Verge》採訪時表示:“你可以爭論通用智能是類似於人類水平的智能,還是類似於人類加人類的智能,或者是某種遙遠未來的超級智能。但對我來說,重要的部分其實是它的廣度,即智能具有所有這些不同的能力,你必須能夠推理並擁有直覺。”
05.Llama 3與Llama 2相比如何?
扎克伯格還宣布對培訓基礎設施進行大量投資。到2024年底,Meta公司打算擁有大約35萬個英偉達H100 GPU。
這將使Meta公司的可用計算資源總量達到60萬個H100計算當量,其中包括他們已經擁有的GPU,目前只有微軟擁有與之相當的計算能力儲備。
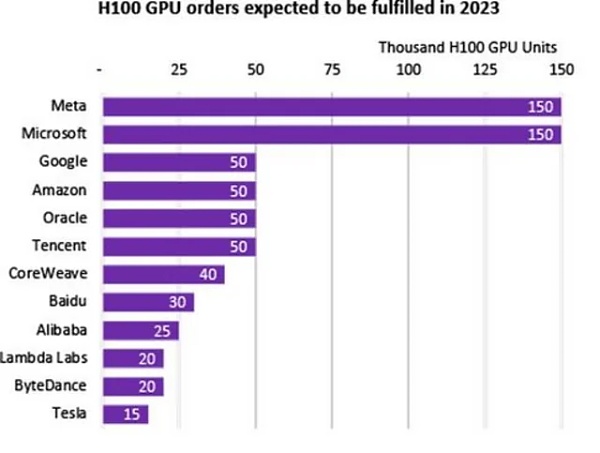
因此,我們有理由相信,即使Llama 3型號並不比前代型號大,其性能也會比Llama 2型號有大幅提升。
Deepmind在2022年3月發表的一篇論文中提出了Llama的性能會大幅提升的假設,隨後Meta公司的模型和其他开源模型(例如法國Mistral公司的模型)也證明了這一點,即在更多數據上訓練較小的模型比在較少數據上訓練較大的模型能產生更高的性能。
雖然Llama 3模型的規模尚未公布,但很可能會延續前幾代模型的模式,即在70-70億參數模型內提高性能。Meta最近在基礎設施方面的投資必將爲任何規模的模型提供更強大的預訓練功能。
Llama 2還將Llama 1的上下文長度增加了一倍,這意味着Llama 2在推理過程中可以“記住”兩倍的上下文,Llama 3有可能在這方面取得進一步進展。
06.與OpenAI的GPT-4相比又如何?
雖然較小的LLaMA和Llama 2模型在某些基准測試中達到或超過了較大的、參數爲1750億的GPT-3模型的性能,但它們無法與ChatGPT中提供的GPT-3.5和GPT-4模型相媲美。

隨着新一代模型的推出,Meta似乎有意爲开源世界帶來最先進的性能。
扎克伯格向《The Verge》表示:“Llama 2並不是業界領先的模型,但卻是最好的开源模型。有了Llama 3及以後,我們的目標是打造處於最先進水平的產品,並最終成爲業界領先的模型。”
07.給未來做准備
有了新的基礎模型,就有了通過改進應用程序、聊天機器人、工作流程和自動化來獲得競爭優勢的新機會。
走在新興發展的前列是避免落後的最佳途徑,採用新工具能使企業的產品與衆不同,並爲客戶和員工提供最佳體驗。
 打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 元宇宙之心 > Meta計劃7月發布Llama 3大模型 小扎是怎么放狠話的?
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 元宇宙之心 > Meta計劃7月發布Llama 3大模型 小扎是怎么放狠話的?
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:Meta計劃7月發布Llama 3大模型 小扎是怎么放狠話的?
地址:https://www.sgitmedia.com/article/24632.html
相關閱讀:
- 鐵腕SEC主席Gary Gensler 終在特朗普就任時卸職 2024-11-22
- 時代周刊:馬斯克如何一步步成爲“造王”者? 2024-11-22
- 幣安CEO寄語:帶領幣安進入加密貨幣新時代的一年 2024-11-22
- 低利率低通脹 特朗普變身埃蘇丹? 2024-11-22
- 金融巨頭策略轉變?嘉信理財進軍Crypto市場 2024-11-22
- 比特幣都10萬了 巨頭下重注的元宇宙卻還在沉默?它還會回來嗎? 2024-11-22
- 馬斯克和維韋克發布:政府效率辦公室(DOGE)的改革計劃(全文) 2024-11-22
- AI耶穌誕生 它真能成爲耶穌嗎? 2024-11-22

